Why use PyTorch Lattice?
Many current state-of-the-art machine learning models are built using a black-box modeling approach, which means training an opaque but flexible model like a deep neural net (DNN) on a dataset of training examples. While we know the structure of DNNs, it is precisely this structure that makes them black-box models.
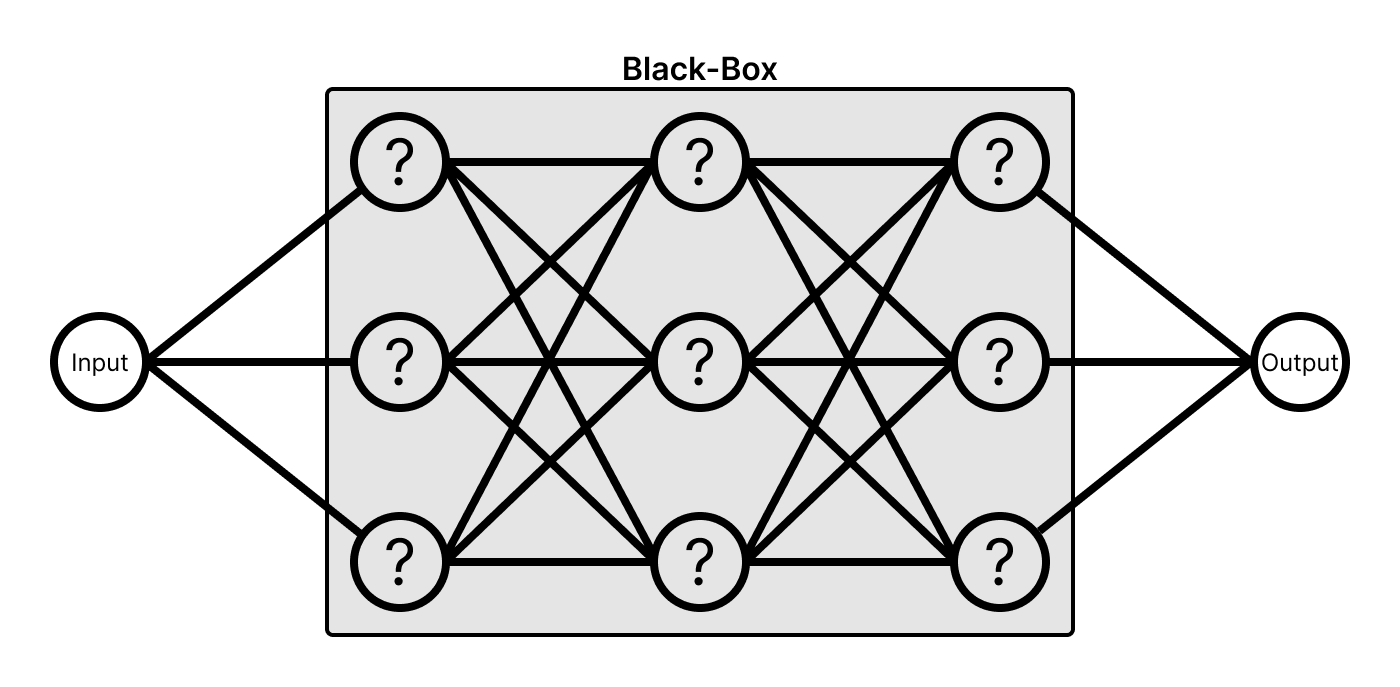
Every feature goes through a series of fully-connected layers, meaning every node is a function of every feature. Each node becomes a function through training, but the purpose of any individual node is hidden from the user -- only the model knows. How are we supposed to understand or trust a model's predictions if we don't know what any function within the larger system is doing?
Furthermore, black-box models are 100% reliant on the training data. This means that if a model is producing funky predictions, the solution is to either (1) find more training data and re-train the model, or (2) discover a new model structure tailored to the given task. Neither option is a great choice for the majority of data scientists and machine learning practitioners -- unless they work at a large tech company with the resources dedicated to making such solutions possible -- since gathering and cleaning data and discovering new model structures are not only inherently difficult tasks but also time and cost intensive.
But every data scientist and machine learning practitioner, even those at large tech companies, has run into issues where their model behaves unexpectedly in the wild because the training data is too different from live examples, especially since real-world data distributions change frequently.
So, what can we do to reduce the risk of unknown outcomes?
Understanding The Why Of A Model's Predictions
Without the why, a model's prediction is opaque and difficult to trust, even if it's correct. That's why understanding the why is such an active area of research. It's worth noting that there is a distinction between the two approaches in this field that have seen success: Explainability vs. Interpretability.
Explainability focuses on explaining a black-box model's predictions, which is a top-down approach. The benefit of this approach is that resulting methods apply to black-box models, meaning that they apply to any machine learning model. The current state-of-the-art explainability technology is Shapley values, which we can use to determine the importance of each feature for any machine learning model. Perhaps we train a model to predict the price of a house and learn that zip code is the most important feature. The downside of this approach is the limitations inherent to a black-box structure. While this knowledge of importance provides general insight into how the model is making predictions, does it really explain anything? How a particular zip code impacts a model's predictions is still a mystery.
The sad truth is that Explainability often only points to common sense results -- not illuminating insights.
Interpretability is instead a bottom-up approach focused on providing transparency through calibrated models structured specifically with illuminating insights and control in mind. The downside to this approach is that it requires more input from the user; however, this input is invaluable for the model to understand the system in the way we expect. The benefit of this approach is that the resulting models are much easier to understand. For example, we can analyze the way a calibrated model handles individual features by charting the corresponding feature calibration layer -- the layer specific to calibrated models that calibrates the initial input for later layers. For a categorical feature like zip code, the result will be a bar chart that shows us the calibrated values for each zip code. So now we know not only that zip code is the most important feature, but also the relative impact each zip code has on the predicted price. This is a far more granular understanding.
Consistently Predicting How A Model Will Behave On Unseen Examples
Okay, so we have a way to dig deeper and understand the why. That's great. But we have to remember that why is an afterthought -- for example, something went wrong and we want to know why. Of course, the why is incredibly useful and plays a big part in understanding how a model will behave, but it does not provide any guarantees on future behavior. Trust comes from the ability to predict behavior, so the more consistently one can predict a model's behavior, the more one can trust that model.
Consider using a machine learning model to predict credit score where one of the input features is how late someone is on their payments. The behavior we want and expect is for the model to produce a better credit score for someone who pays their bills sooner, all else being equal. We can imagine that it would be unfair to penalize someone for paying their bills sooner. Even if we can understand the why, with black-box modeling we have no such guarantee.
With calibrated modeling, we can constrain the shape of the model's function to provide certain guarantees. We call these shape constraints, and they come in many different flavors. The feature for payment lateness is a perfect fit for a decreasing monotonicity shape constraint. A decreasing monotonic functions's output always increases if the input decreases, and vice-versa. We want the model (function) to produce a higher credit score (output) if payment lateness (input) decreases, all else being equal. With PyTorch Lattice, just configure this behavior before training and it will be guaranteed. Pretty cool, right?
Now, if you're not here to predict credit scores, you might be wondering how shape constraints can help you. What about the age of a house when predicting its price? Time since last repair for predictive maintenance? Number of similar items purchased when trying to predict a sale?
Hopefully it's clear that many real-world features operate under these or similar constraints because they are part of real-world systems with certain fundamental rules. While we can hope that black-box models learn what we would expect from data, the ability to guarantee the behaviors we expect enables a higher level of trust in a model and eliminates toil.